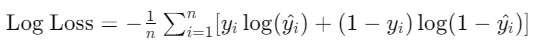이 글은 <Reliable Machine Learning, Cathy Chen, Niall Richard Murphy, Kranti Parisa, D. Sculley, Todd Underwood> 5장 Evaluating Model Validity and Quality을 참고하여 작성했습니다.
Chapter 5. Evaluating Model Validity and Quality (2) - Evaluating Model Quality
모델의 Quality 테스트를 구성할 때 크게 두 가지를 구성해야 합니다.
1. 테스트 데이터를 어떻게 구성할 것인가
2. 어떤 지표로 평가할 것인가
각각에 대해서 알아보겠습니다.
테스트 데이터 구성 방법
1. Held-out test data
전체 데이터에서 무작위로 선택하여 테스트 데이터를 만드는 방법입니다. 이 방식은 학습 데이터와 테스트 데이터의 분포가 유사할 때 유용합니다. 그러나 날짜별 주가 데이터와 같이 시간적 순서가 중요한 문제에서는 무작위 선택을 피해야 합니다. 미래 데이터가 학습에 포함될 위험이 있기 때문입니다.
2. Progressive validation (=BackTesting)
과거 데이터를 사용하여 모델이나 전략의 성능을 평가하는 방법입니다. 이 과정에서는 실제 역사적 데이터를 바탕으로 모델이 얼마나 잘 작동했는지를 분석하여 성과를 예측합니다. 백테스팅은 전략의 유효성을 검증하고, 실제 적용 시의 잠재적 문제를 사전에 발견하는 데 유용합니다.
3. Golden sets
때때로 모델의 성능을 검증하기 위해, 훈련에는 전혀 사용하지 않은 순수한 테스트 데이터, 즉 Golden Set을 사용하는 것도 유익합니다. 두 번째 방법에서는 테스트 데이터가 지속적으로 변하기 때문에, 모델의 성능이 저하된 것인지, 문제의 난이도가 증가한 것인지 판단하기 어려울 수 있습니다. 이럴 때 Golden Set을 보조적으로 활용하면 모델 성능을 평가하는 데 도움이 될 수 있지만, Golden Set이 항상 최신 트렌드를 반영하지는 않으므로 보조 자료로 활용하는 것이 적절할 수 있습니다.
4. Stress-test distributions
모델이 극단적인 상황이나 비정상적인 조건에서도 잘 작동하는지 평가하기 위해 테스트 데이터를 구성할 수 있습니다. 예를 들어, 금융 모델에서는 2008년 금융 위기와 같은 극단적인 금융 사건을 반영한 데이터를 사용하여 스트레스 테스트를 수행할 수 있습니다. 이러한 테스트를 통해 모델이 예외적인 상황에서도 어떻게 동작하는지 평가할 수 있습니다.
5. Sliced analysis
특정 특성 값에 기반하여 필터링한 데이터를 활용해 테스트 데이터를 구성하는 방법입니다. 예를 들어, 나스닥 지수가 3% 하락한 날의 데이터를 수집하여 테스트 데이터를 만들 수 있습니다. 이 접근법을 통해 특정 조건에서 모델의 성능을 더욱 세밀하게 평가할 수 있습니다.
6. Counterfactural testing
실제 데이터와 반대되는 방식의 테스트 데이터를 새로 구성하여, 해당 상황에서는 모델이 어떻게 동작하는지 확인하는 테스트 방식입니다. 예를 들어, 특정 회사의 주가를 예측하는 모델이 있다고 가정했을 때, 실제로는 해당 회사가 부정적인 뉴스로 인해 주가가 하락했지만, 만약 긍정적인 뉴스가 발표되었다면 주가는 어떻게 변화했을지를 분석합니다. 이를 통해 모델이 뉴스 이벤트에 어떻게 반응하는지를 평가할 수 있습니다.
Useful Evaluation Metrics
평가 지표로는 크게 세 분류가 있습니다: Canary Metric, Classification Metric, Regression and ranking Metric.
각 카테고리에서 사용하는 지표는 무엇이 있는지 알아보겠습니다.
1. Canary Metrics
본 지표들은 모델에 심각한 문제가 있는지 알려주는 유용한 지표들입니다. 물론 카나리 지표가 양호하다고 해서 모델이 완벽하다는 것은 아니라는 것을 명심해야 합니다.
Bias
모델의 예측값 분포와 실제 데이터 분포가 유사한지를 나타냅니다. 실제 분포와 모델의 예측값 분포가 지나치게 다르다면, 이는 모델에 문제가 있을 수 있다는 신호일 수 있습니다. 그러나 두 분포가 완전히 일치한다고 해서 모델이 반드시 좋은 것은 아닙니다.
Calibration
모델이 확률값이나 수치를 예측하는 경우, 사용자는 이 예측값에 변형을 가할 수 있습니다. 예를 들어, 모델이 확률을 예측한 후, 특정 임계치를 설정하여 그 이상일 경우 긍정으로, 그 이하일 경우 부정으로 분류하도록 조정할 수 있습니다. 이러한 보정(calibration) 이후의 모델 성능을 평가하는 방식을 의미합니다.
2. Classification Metrics
본 지표들은 분류 문제에서 주로 사용되는 지표들입니다.
Accuracy
Accuracy(정확도)는 모델의 성능을 평가하는 지표 중 하나로, 전체 예측 중에서 올바르게 예측한 비율을 나타냅니다. 간단히 말해, 모델이 얼마나 정확하게 예측했는지를 측정하는 지표입니다. 정확도는 모델의 전반적인 성과를 평가하는 데 유용하지만, 클래스 불균형이 심한 문제에서는 추가적인 성능 지표(예: 정밀도, 재현율, F1-score 등)를 함께 고려하는 것이 필요합니다.
Precision and recall
Precition(정밀도)는 모델이 긍정으로 예측한 샘플 중 실제로도 긍정인 샘플의 비율을 나타냅니다. 즉, 모델이 긍정이라고 예측한 것들 중 얼마나 정확한지를 측정합니다. Recall(재현율)은 실제 긍정 샘플 중 모델이 긍정으로 올바르게 예측한 비율을 나타냅니다. 즉, 실제 긍정 샘플을 얼마나 잘 잡아내는지를 측정합니다. 정밀도와 재현율은 상호 보완적인 지표로, 모델의 성능을 보다 정확하게 평가하기 위해 함께 사용됩니다. 정밀도가 높으면 긍정 예측의 신뢰성이 높고, 재현율이 높으면 실제 긍정 샘플을 잘 잡아낸다는 의미입니다. 이 두 지표를 종합적으로 고려하여 모델의 성능을 평가하는 것이 중요합니다. 특히, F1-score와 같은 조화 평균 지표를 사용하여 정밀도와 재현율 간의 균형을 평가할 수 있습니다.
AUC-ROC
ROC Curve는 다양한 임계값(threshold)에서의 True Positive Rate (TPR)와 False Positive Rate (FPR)을 플롯한 그래프입니다. ROC Curve를 사용하면 모델의 성능을 시각적으로 평가할 수 있습니다. AUC는 ROC Curve 아래의 면적을 의미합니다. 이 값은 모델의 분류 성능을 요약하여 나타내는 수치입니다. AUC-ROC는 분류 모델의 전반적인 성능을 종합적으로 평가하는 데 유용한 지표입니다. 다양한 임계값에서의 모델 성능을 평가할 수 있으며, 클래스 불균형이 있는 데이터셋에서도 효과적으로 모델의 성능을 비교할 수 있습니다.

3. Regression and ranking metrics
본 지표들은 Regression이나 Ranking 문제에서 사용되는 지표입니다.
Mean squared error
MSE는 예측값과 실제값 사이의 차이를 제곱하여 평균한 값입니다. 큰 오차를 강조하고, 수학적 최적화에 유리하지만 아웃라이어에 민감합니다.
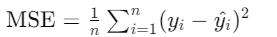
Mean absolute error
MAE는 예측값과 실제값 사이의 절대적인 차이를 평균한 값입니다. 이해하기 쉽고 아웃라이어에 강하지만 미분 불가능하고 큰 오류를 강조하지 않습니다.
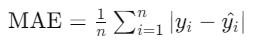
Log loss
Log Loss는 예측된 확률과 실제 레이블 간의 차이를 측정합니다. 확률적 예측을 평가하며 클래스 불균형에 적합하지만 해석이 복잡하고 수치적 불안정성이 발생할 수 있습니다.